前天訓練了模型~今天我們要評估一下模型的效果。
常見的評估方式,就是準確度跟混淆矩陣。先上程式碼:(其實先前程式碼裡面有)
# 進行預測
y_pred_train = rf_model.predict(X_train)
y_pred_test = rf_model.predict(X_test)
# 計算準確度
train_accuracy = accuracy_score(y_train, y_pred_train)
test_accuracy = accuracy_score(y_test, y_pred_test)
# 計算混淆矩陣
confusion_train = confusion_matrix(y_train, y_pred_train)
confusion_test = confusion_matrix(y_test, y_pred_test)
# 輸出結果
print("訓練集準確度:", train_accuracy)
print("測試集準確度:", test_accuracy)
print("訓練集混淆矩陣:")
print(confusion_train)
print("測試集混淆矩陣:")
print(confusion_test)
準確度衡量了模型正確預測的樣本數佔總樣本數的比例。數學式:

通常用於分類問題的評估,一般來說會用準確度當作訓練的目標。
訓練集準確度是模型在訓練數據集上的性能評估指標,代表模型對訓練數據的預測準確度,經過訓練的模型一般需要在訓練集準確度達到約100%的準確度。
測試集準確度是對於測試集的分類效果,本次模型的分類準確度大約落在45%,比亂猜33%好一點XD想當然只用這點數據還不夠,這部分就請讀者在Talib多多測試瞜~
混淆矩陣是用於評估分類模型性能的工具。它包含四個關鍵詞:
真陽性是指模型正確地預測正類別的樣本數,即實際為正類別且被模型預測為正類別的樣本數。
假陽性是指模型錯誤地將負類別的樣本錯誤地預測為正類別的樣本數,即實際為負類別但被模型誤認為正類別的樣本數。
真陰性是指模型正確地預測負類別的樣本數,即實際為負類別且被模型預測為負類別的樣本數。
假陰性是指模型錯誤地將正類別的樣本錯誤地預測為負類別的樣本數,即實際為正類別但被模型誤認為負類別的樣本數。
混淆矩陣的信息可以用來計算各種性能指標,如準確度、精確度、召回率等,以評估模型的表現。
以下是本次的混淆矩陣
| 預測為類別 1 | 預測為類別 0 | 預測為類別 -1 | |
|---|---|---|---|
| 真實為類別 1 | 5157 | 7701 | 7069 |
| 真實為類別 0 | 3683 | 18632 | 7006 |
| 真實為類別 -1 | 4497 | 10510 | 10407 |
他是一個3x3的矩陣,包含9種狀態,可以發現一個關鍵,我們其實相比看漲結果沒漲,更在意看漲結果大跌的結果,因此我們可以簡化出一種混淆矩陣:
| 預測看多或預測中立 | 預測看空 | |
|---|---|---|
| 實際上漲或實際持平 | 35173 | 14075 |
| 實際下跌 | 15007 | 10407 |
在這裡面我們可以更加地明確地看到我們會希望以下兩種情況的預測可以歸零:
上述兩種狀況越少,單筆的風險就越低。
因此可以算出務實準確度:

數值真的有點低,還需要多花時間處理。
前面的狀況有出現很多的錯誤,分別是:
在實踐中,在數據收集和準備過程中無意中引入了目標變量的間接表示。這個時候我們檢視一件事情是我們將每天數據加上前四天的數據做為輸入,並且隨機取樣。聽起來沒有太大問題,但是無意間你會發現可能 9/18包含9/18~9/14的數據 9/17包含9/17~9/13的數據 可能訓練的時候已經有訓練到 9/18的資料,此時測試集出9/17的數據時可能就會洩漏了 9/17~9/14的數據先給模型知道,他在測試集的時候就背書就好。
想要改進這個錯誤我們可以改採分區取樣:
我們在做測試時,如果將測試的資料只限定在固定某一時期,這樣可能會出現我們有用的特徵只分布在某個區域,其他區域密度降低,導致對於未來可能會有一些與預測偏差。解決這樣的問題最直接的方式就是交叉驗證。
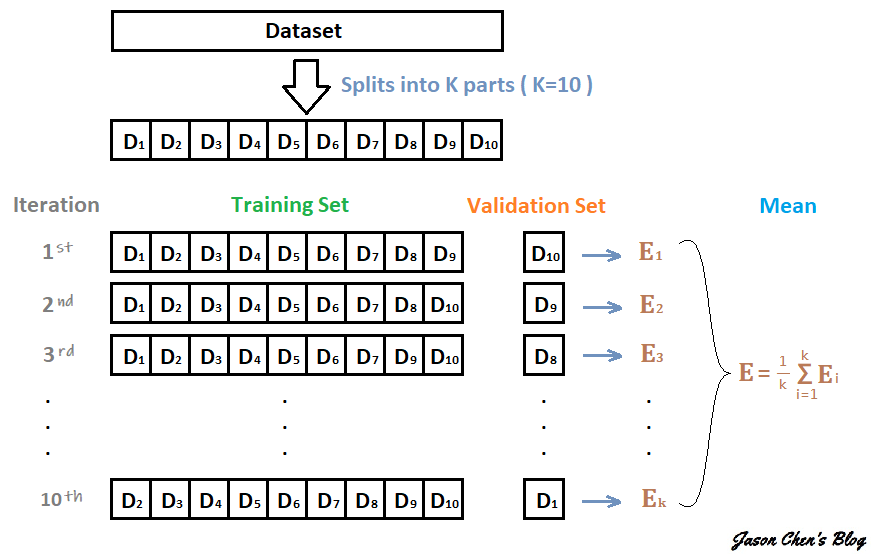
在少量樣本的情況下,我們往往會遇到驗證集資料不具代表性的問題。這意味著從這一小部分驗證集中抽取的樣本可能無法全面反映整個數據分布。因此,有時我們可能會在某些樣本上驗證模型表現良好,但在另一組樣本上卻表現糟糕。
為了克服這個問題,我們使用交叉驗證方法來更有效地評估模型的性能。這種方法涉及將數據集分為多個子集(稱為折數),然後多次訓練和驗證模型,每次使用不同的子集作為驗證集,其餘子集用於訓練。這樣,我們可以綜合考慮各種不同的數據組合,確保模型在不同子集上的表現都得到評估,從而更可靠地評估模型的優劣表現。
這裡討論三種交叉驗證的方式:
交叉驗證是一種評估機器學習模型性能的方法。它的過程如下:首先,將數據分成 K 份,其中 K-1 份用作訓練集,剩下的 1 份用作驗證集。然後,使用訓練集來訓練模型,並在驗證集上計算驗證誤差。從未被用作驗證集的數據中選擇一份作為新的驗證集,同時之前的驗證集重新加入訓練集中。這個過程重複 K 次,確保每份數據都被用作驗證集一次。每次都計算出一個驗證誤差。最後再將這 K 個驗證誤差取平均值,得到一個綜合的性能指標,用於評估模型的好壞。這個指標通常被用來選擇最佳的模型或調整模型的超參數。
sklearn中有一個寫好的函式可以用,未來我們會使用這個。
留一法交叉驗證更加的極端,他就是在分拆訓練集與驗證集時,將驗證集只留下一筆資料,因此有幾筆資料我們就會訓練幾個模型,會非常非常耗時,但是可以極度趨近真實的期望值。
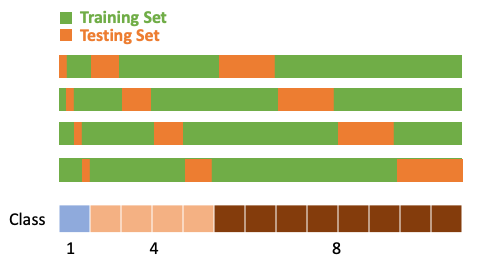
分層交叉驗證是一種用於評估機器學習模型性能的方法。在某些情況下,特別是在處理不平衡類別分佈的分類任務時,需要確保每個交叉驗證折疊(Fold)中的類別比例與整體數據集中的比例相似。例如,如果一個分類任務涉及三個類別A、B、C,它們的比例是1:4:8,那麼每個Fold中的A、B、C的比例也應該是1:4:8。為了實現這種分層抽樣,可以按以下步驟進行:
應對於標籤不平衡的題目時很好用。
# 引入必要的套件
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.model_selection import TimeSeriesSplit
import joblib
# 1. 數據讀取與檢查
data = pd.read_csv('label_data_with_stoch.csv')
# 2. 創建具有5天歷史資料的新特徵
columns_to_use = ['slowd_5_3_3', 'slowk_5_3_4', 'slowd_5_3_4', 'slowk_5_4_3',
'slowk_5_5_4', 'slowd_5_5_4', 'slowd_5_5_5', 'slowd_6_3_3',
'slowd_6_4_4', 'slowk_6_5_3', 'slowd_6_5_5', 'slowk_7_3_3',
'slowk_7_4_4', 'slowd_7_4_4', 'slowk_7_5_3', 'slowd_7_5_5',
'slowd_8_3_3', 'slowd_8_4_3', 'slowd_8_4_4', 'slowd_8_4_5',
'slowk_8_5_4', 'slowk_9_3_3', 'slowd_9_3_3', 'slowk_9_4_3',
'slowk_9_5_4', 'slowd_9_5_5', 'slowd_10_3_3', 'slowk_10_3_5',
'slowk_10_4_3', 'slowd_10_4_3', 'slowd_10_4_4', 'slowk_10_5_3',
'slowd_10_5_5'
]
for col in columns_to_use:
for i in range(1, 6):
data[f'{col}_lag_{i}'] = data[col].shift(i)
data = data.dropna() # 移除含有 NaN 值的列
# 3. 數據預處理
# 定義K-Fold交叉驗證
n_splits = 5
tscv = TimeSeriesSplit(n_splits=n_splits)
# 初始化變數以儲存驗證結果
avg_train_accuracy = 0
avg_test_accuracy = 0
avg_confusion_train = np.zeros((2, 2))
avg_confusion_test = np.zeros((2, 2))
# 迭代進行K-Fold交叉驗證
for train_idx, test_idx in tscv.split(data):
# 選擇訓練集和測試集
train_data = data.iloc[train_idx]
test_data = data.iloc[test_idx]
# 選擇特徵和目標變量
features = [col for col in data.columns if '_lag_' in col]
X_train = train_data[features]
y_train = train_data['label']
X_test = test_data[features]
y_test = test_data['label']
# 4. 建立隨機森林模型
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
# 進行預測
y_pred_train = rf_model.predict(X_train)
y_pred_test = rf_model.predict(X_test)
# 計算準確度
train_accuracy = accuracy_score(y_train, y_pred_train)
test_accuracy = accuracy_score(y_test, y_pred_test)
# 計算混淆矩陣
confusion_train = confusion_matrix(y_train, y_pred_train)
confusion_test = confusion_matrix(y_test, y_pred_test)
# 累加驗證結果和混淆矩陣
avg_train_accuracy += train_accuracy
avg_test_accuracy += test_accuracy
avg_confusion_train += confusion_train
avg_confusion_test += confusion_test
# 計算平均準確度
avg_train_accuracy /= n_splits
avg_test_accuracy /= n_splits
avg_confusion_train /= n_splits
avg_confusion_test /= n_splits
# 輸出平均結果和混淆矩陣
print(f"平均訓練集準確度: {avg_train_accuracy}")
print(f"平均測試集準確度: {avg_test_accuracy}")
print("平均訓練集混淆矩陣:")
print(avg_confusion_train)
print("平均測試集混淆矩陣:")
print(avg_confusion_test)
今天先到這裡~ 我要去睡覺了~!!!


 iThome鐵人賽
iThome鐵人賽